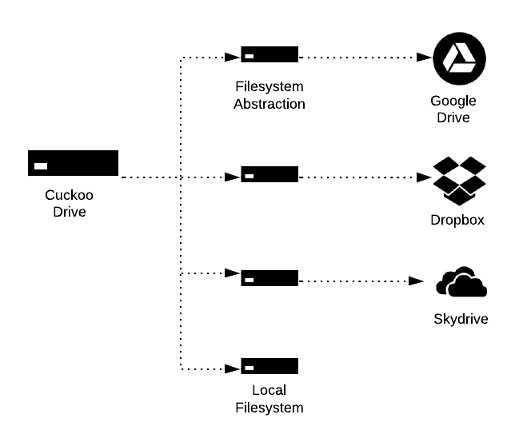
Cuckoo Drive Architecture
I want to abstract the fact, that the Cuckoo Drive is just a composition of many cloud storages. It should work the same way as if you use your local harddrive with a special filesystem on it. This automatically allows many tools and possibilities that already exist (like the great rsync) to interact with the CuckooDrive.
Cuckoo Drive is a Filesystem Composition
My first thought was to write a FUSE implementation, but then I stumbled across PyFilesystem which has alot of the functionality I need already built in and provides an excellent filesystem interface I can test and program against.
The various cloud storages are simply implemented as a PyFilesystem and could theoratically even be mounted for direct access. I don’t need to define a common interface and I can look at already existing implementations of cloud storages as a PyFilesystem. These filesystems are combined into one big superdrive. We now have abstracted the problem of distributing the files across the cloud systems to a very general problem of distributing files of a drive across other drives. This is easy testable, understandable and perhaps even applicable to other scenarios.
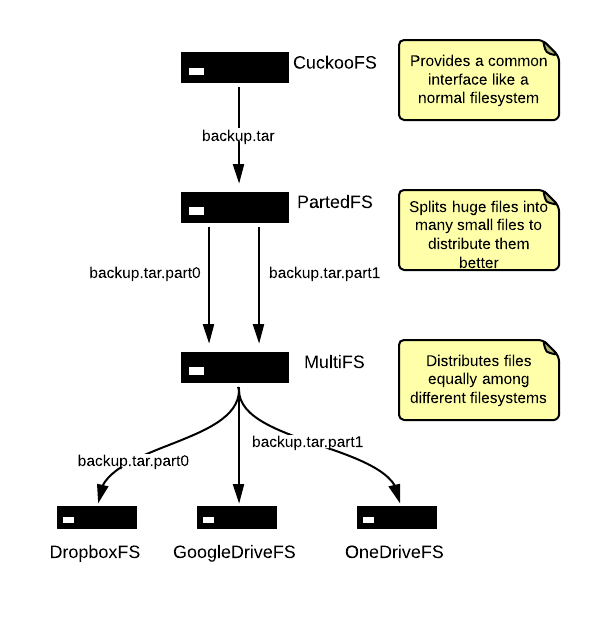
Concrete Implementation
I don’t want to deal with too many problems at one time, that is why the Cuckoo Drive consists out of many layers (where you can later plugin things like encryption and redundancy). One problem is, that we need many small files because most cloud storages have a maximum file size limit. It is also better to deal with many small files for caching and bandwidth reasons. But I don’t want to deal constantly with the fact that one file actually consinsts of several smaller files, the PartedFS implementation will take care of this. For users it will look as if it is a single file, but behind the scenes they are splitted into many files. The MultiFS takes care of distributing the many files equally on many other remote filesystems.